画像生成AI「Stable Diffusion」を Windows PC上で使える高機能ソフト「Stable Diffusion web UI (AUTOMATIC1111版)」を導入したので、ソフト導入後にやっておいた方が良いおすすめの設定や入れておいた方が良い拡張機能について随時メモを追加しています。
(記事内容は最新機能の追加や使用に合わせて更新する予定。)
なお掲載しているソフト画面は日本語化後のものです。
日本語化やソフト自体の導入に関しては以下のページに記載しているので適宜ご参照ください。
2025/1/13 (更新) 現在は Stable Diffusion web UI (AUTOMATIC1111版) を導入する非常に簡単な方法が存在するため、本ページの手順を一から実施する必要はなくなりました。 面倒な Py[…]

高速化設定 (xFormers の有効化)
xFormers を有効化すると画像生成の所要時間を短縮し、かつ VRAM 使用量を削減できるようです。
導入方法
以下リンク先のサイトで画像付きの詳しい設定方法が掲載されていましたのでご参照ください。
リンク:【高速化】Stable Diffusionの生成時間を短縮するxformersの導入方法
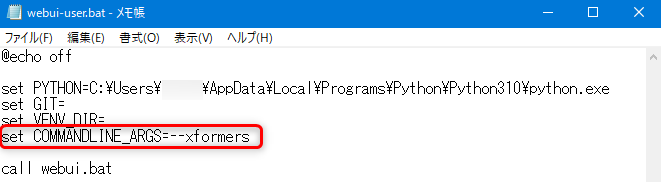
※「set COMMANDLINE_ARGS=」の直後に入力する文字列は「--xformers」です。(リンク先サイトの文章中では「–xformers」になってしまっているので注意)
サイトの手順に従い、上記画像のように webui-user.bat を編集すればOKです。
編集後、webui-user.bat から起動すると初回は xFormers のインストール工程が入ります。
インストール終了後に web UI の画面が通常通り起動します。
画面下の画像赤線のところに xformers のバージョンが正常に表示されていればインストールが正しくできています。

※インストールされていない状態では「xformers: N/A」という表記でバージョンの数字が表示されません。
効果
ちゃんと厳密に測定していないのであくまで参考値(しかも n=1)ですが、私の環境 (GeForce RTX 2060 SUPER) でも確かに画像生成速度は若干向上しました。
平均速度:3.41 → 2.84 (秒/枚)
VRAM消費量:5579 → 5171 (MB)
旧バージョンの xformers の問題について
なお xformers のバージョンが 0.0.20 より前の時代は、同一の設定パラメータであるにもかかわらず毎回微妙に異なる画像が生成されてしまう仕様(不具合)がありましたが現在は修正され、xformers を利用するデメリットが無くなりました。
(※情報源:Xformers · AUTOMATIC1111/stable-diffusion-webui Wiki)
2023/10/04時点では、上記手順で xformers をインストールすればバージョン 0.0.20 以降がインストールされるため以下の不具合を心配する必要はありません。
xFormers 有効化時は同一の設定パラメータであるにもかかわらず少し異なる画像が生成されてしまうことがあります。 (仕様)

"a beautiful photo of a cute cat", Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2618586753, Size: 512x512, Model hash: 8fa720422e, Model: sd-v1-5-fp16
上記3枚の画像はすべて同一パラメータで生成しています。
実際に使ってみると、実行するたびに生成する画像が結構変化しますね…/ᐠ•ω• ;ᐟ\
再現性が重要な場合は xformers の使用は控えたほうがいいかもしれません。
web UI を自動起動する設定
※現在のバージョンでは以下の設定を行わなくても web UI 画面が自動で立ち上がるようになっています。
通常は web UI 起動後に自分で http://127.0.0.1:7860 にアクセスして web UI のメイン画面を自分で開く必要がありますが、これを自動でやってくれる設定があります。
webui-user.bat の set COMMANDLINE_ARGS= の行に、「--autolaunch」オプションを追加します。
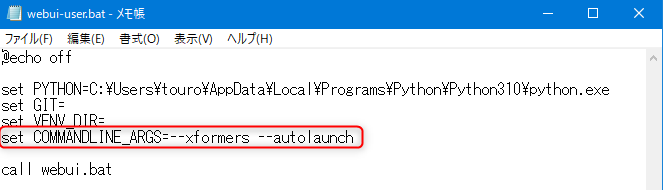
set COMMANDLINE_ARGS=--xformers --autolaunch
ㅤ
● xFormers は使わない場合
set COMMANDLINE_ARGS=--autolaunch
上記コマンドのいずれかをコピペしてください。
次回以降、webui-user.bat から起動すると、起動処理完了後に自動でブラウザの web UI 画面が立ち上がるようになります。(便利!)
おすすめ設定
※おすすめと称していますがあくまで個人的な好みに基づいた設定です。各自お好みでどうぞ。
※以下、設定画面の設定項目名をそのまま見出しにしています。

各設定を変更したら、必ず設定画面上部の「設定を適用」ボタンを忘れずに押してください! (押さないと設定が反映されません)

画像/グリッド画像の保存
・img2img で使った画像を自動で別フォルダに保存
沢山画像があるとどの画像を img2img に使ったか分からなくなりがちなので、img2img 時に読み込んだ画像を自動で別のフォルダに保存(コピー)するオプションをONにしています。
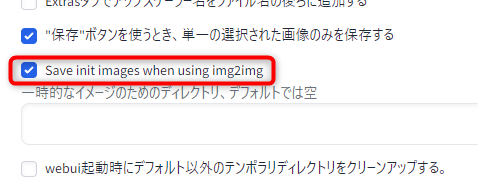
設定項目 Save init images when using img2img (img2img使用時に初期画像を保存する) をONにします。
すると、画像の標準出力先(outputsフォルダ)に新しく「init-images」フォルダができ、その中に img2img 用に読み込んだ画像が保存されるようになります。
※保存先の指定は次の「保存するパス」設定画面で行えます。
・出力画像名の形式を変更 (画像名にモデル名を含める)
デフォルトだと「00003-2618586752.png」のように『連番-シード値』のファイル名形式です。
これを自分の好きなパターンにカスタマイズできます。
「ファイル名のパターン」入力欄でファイル名形式を指定します。
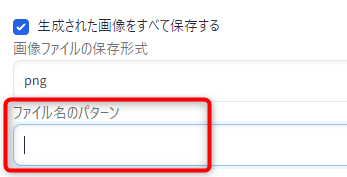
ファイル名パターンには大かっこ付きの以下の項目を入れることができ、画像生成時に実際の値に置き換わります。
[seed]:シード値
[steps]:ステップ数
[cfg]:CFG-Scale値
[width]:出力画像の幅
[height]:出力画像の高さ
[styles]:選択したスタイルの名前
[sampler]:サンプラー
[model_hash]:モデルのハッシュ値
[model_name]:モデル名
[date]:生成した日付 (2023-12-31)
[datetime]:生成した日付時刻 (20231231123400:年月日時分秒)
[job_timestamp]:タイムスタンプ
[prompt_hash]:プロンプトをハッシュ化した文字列
[prompt]:プロンプト(スペースは _ に置換)
[prompt_no_styles]:プロンプト、スタイル無し
[prompt_spaces]:プロンプト、スタイル有り (スペースはそのまま)
[prompt_words]:プロンプト、カッコ類やカンマは除去
[batch_number]:バッチ番号 (画像生成のたびにリセットされる連番)
[generation_number]:生成番号 (全体を通しての連番)
[hasprompt]:プロンプトに特定文字列があった場合だけ変える (※公式ドキュメント参照)
[clip_skip]:Clip skip値各項目の詳しい説明と設定時の具体的な名前例は公式ドキュメントが分かりやすいのでそちらをご参照ください。
※設定可能パターンの一覧は modules/images.py を見れば確認できます。
個人的にはモデル名が画像ファイル名に含まれていると結構便利なので、私は以下のファイル名形式を指定しています。
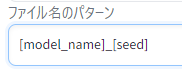
[model_name]_[seed]↑実際のファイル名は「00001-sd-v1-5-fp16_309486940.png」といった感じになります。(連番-モデル名_シード値.png)
・その他 お好み設定
- グリッド画像が不要な場合はお好みで「グリッド画像を常に保存する」をオフに
- 顔修復や高解像度補助実施前の元の画像も消さずに残しておきたい場合はそれぞれ「顔の修復を行う前に元画像のコピーを保存しておく。」「高解像度補助を行う前に元画像のコピーを保存しておく」をオフに
保存するパス
・お気に入り画像保存フォルダを作る
画像生成画面で「保存」を押した時、表示されている画像は初期設定だと「log」フォルダに保存されます。
生成中に良い画像が出てきたら「保存」を押してそのフォルダにコピーする、といったようにお気に入りフォルダとして使えますが、名前が「logs」だと目立たないのでお気に入りフォルダだと分かる名前に変更します。(お好みで)
設定項目の「保存ボタンで画像を保存するディレクトリ」を「0_Favs」に変更しました。
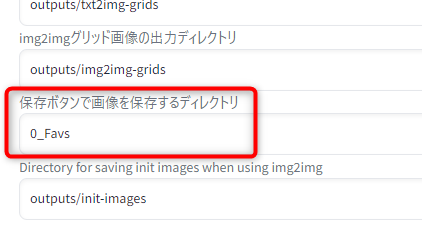
※設定変更前のデフォルト値は「log/images」です。
保存を押した画像はこれで「0_Favs」フォルダ直下に保存されるようになります。
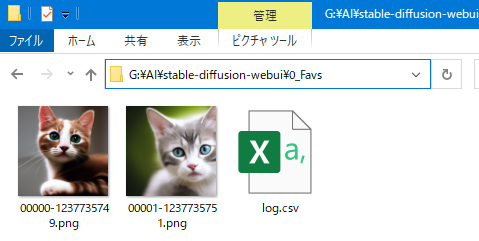
※お気に入りフォルダには log.csv という、保存した画像のプロンプトや設定値が一覧で随時記録されるファイルも同時に生成します。
ディレクトリへの保存
・画像の出力フォルダ名の形式を変更 (プロンプト別に画像をフォルダ分け)
デフォルトでは日付別のフォルダに画像が出力されるようになっています。
このフォルダ名も画像ファイル名の設定と同様にパターンを設定可能です。
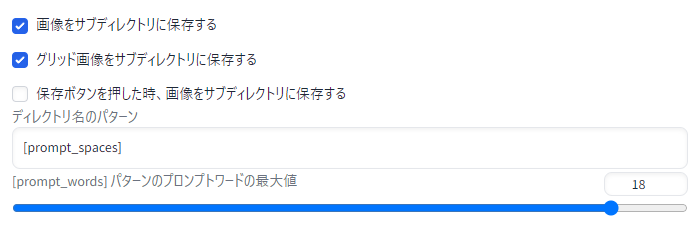
個人的には日付別よりプロンプト別に画像を保存してくれた方が便利なので、ディレクトリ名を以下の形式に変更しています。
・おすすめ(1) 「プロンプト」
[prompt_spaces]
・おすすめ(2) 「モデル名_プロンプト」
[model_name]_[prompt_spaces]ファイル名にモデル名を含めているなら(1)の方が良いかもです。
(同じプロンプトを異なる色々なモデルで試して、同じフォルダに画像出力してその場で比較)
一方で、モデル別に作業スペースをはっきり分けたい場合は(2)の方が良いです。
(異なるモデルなら必ず異なるフォルダに出力される)
アップスケール
※現時点で設定は変更せず
顔の修復
顔修復に使うモデルを CodeFormer から「GFPGAN」の方に変更しました。
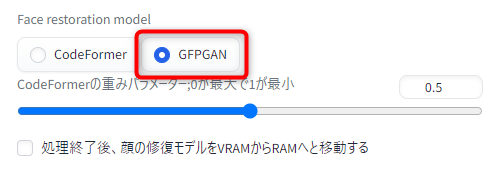
以前両者を比較した際に GFPGAN の方が綺麗に顔を修復できていたので…!
システム設定
※現時点で設定は変更せず
学習
※現時点で設定は変更せず (←今後、学習もやるようになったら設定変更を検討)
Stable Diffusion
・モデルをRAMにキャッシュさせて高速化
お手持ちのPCのRAMにゆとりがある場合 (目安 24-32 GB 以上)、モデル (checkpoit) や VAE を RAM にキャッシュする設定を有効化すれば速度アップが期待できます。
「RAMにキャッシュするcheckpointの個数」「RAMにキャッシュするVAEの個数」を自分の RAM 容量に合わせて増やしてみてください。

モデルや VAE のサイズ分だけ RAM を消費するみたいです。(※↑は適当な個数に設定しただけなので、これで本当に大丈夫かまだ確認できていません)
実際に速度比較された方がいらっしゃったので詳しくは以下のリンク先をご参照ください。
互換性
※変更せず
Interrogate設定
※現時点で設定は変更せず
追加のネットワーク
※現時点で設定は変更せず
ユーザーインターフェース
・よく使う設定をメイン画面上部に追加
「クイック設定」で、お好みで好きな設定項目をメイン画面上部に追加できます。
よく使う設定を変えるためにいちいち設定画面にアクセスする必要がなくなるので大変便利です。
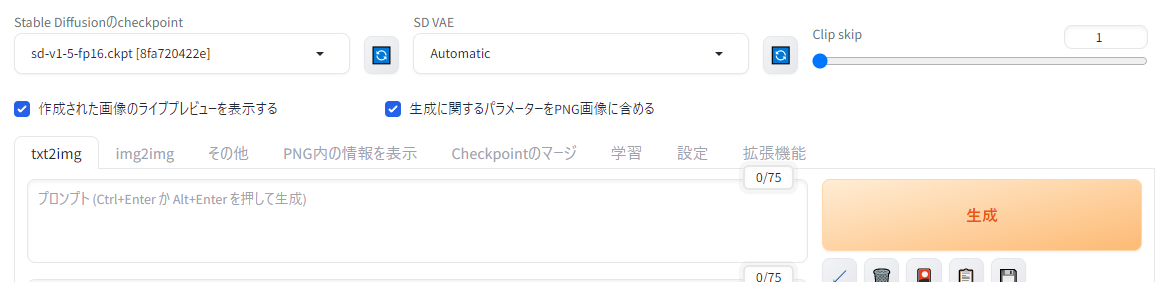
↑「クイック設定」に モデルの選択、VAEの選択、Clip skip 値、ライブプレビューON/OFF、PNGパラメータ情報ON/OFF の5つを追加した場合のソフト画面。
例えば上画像のような画面に設定したい場合は「クイック設定」の入力欄に以下を入れてください。
入力後、設定画面上部の「設定を適用」を押し、「UIの再読み込み」を押せば画面の変更が反映されます。
もちろんこれ以外の設定項目も追加可能です。(順番も変更可能)
指定可能な項目は modules/shared.py で確認できます。
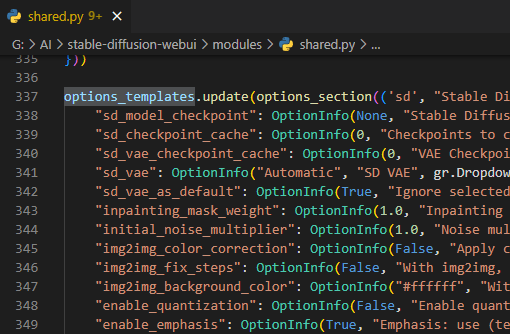
↑options_templates.update(○○… の次の行にある "sd_model_checkpoint", "sd_checkpoint_cache" といったダブルクオーテーションで囲まれた項目名が使用できるものです。
よく使いそうな項目を以下にリストアップしました。
| 追加したい設定項目 | 設定値 |
| モデルの選択 |
sd_model_checkpoint
|
| VAE の選択 |
sd_vae
|
| Clip skip 値 |
CLIP_stop_at_last_layers
|
| グリッド画像を保存するか |
grid_save
|
| 生成したPNG画像にパラメータ情報を含めるか |
enable_pnginfo
|
| 顔修復に使うモデルの選択 |
face_restoration_model
|
| CodeFormer顔復元のweight(重み) |
code_former_weight
|
| 画像のライブプレビューのON/OFF |
live_previews_enable
|
これらを表示させたい順に「 , 」区切りで入力すればOKです。
誤った設定項目を入力ボックスに入れたり、非対応の設定項目をセットしてしまった場合は以下のように web UI にアクセスできなくなります。
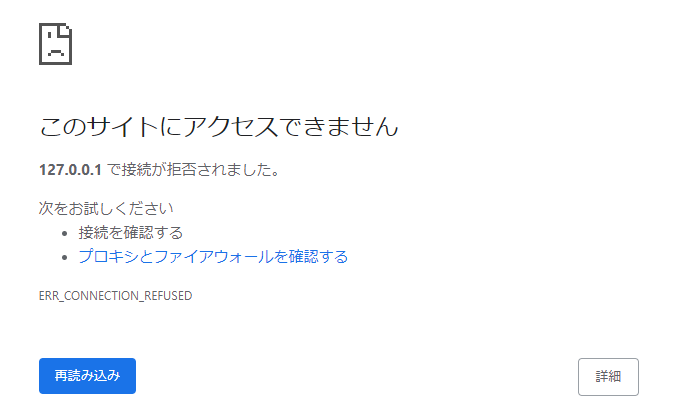
こうなってしまった場合は、設定ファイルを開いてクイック設定を初期値に戻してください。
設定ファイルは「config.json」です。(webui-user.bat と同じ場所)
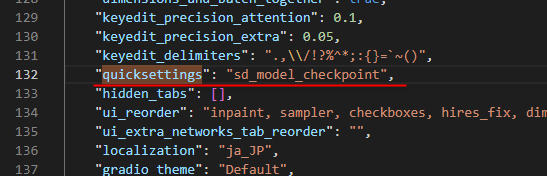
メモ帳やテキストエディタなどで設定ファイルを開いたら Ctrl+F でテキスト内検索を呼び出し、「quicksettings」を検索してください。
そしてヒットした行を下画像のように初期値に書き換えてください。
書き換えが終わったら設定ファイルを保存し、一度 web UI を完全に閉じます。
再度 webui-user.bat から起動して正常に起動すればOKです。
※ quicksettingsに「disabled_extensions」を設定するとこのエラーが必発するので注意
ライブプレビュー
※現時点で設定は変更せず
サンプラーのパラメータ
・(任意) 使わないサンプラーを非表示にする
明らかに使わないサンプラーもあるので、使わないサンプラーは隠しておくことをおすすめします。
(チェックを入れたサンプラーは画像生成画面の「サンプリング方法」の選択肢に表示されなくなるためスッキリします)
後処理
※現時点で設定は変更せず
おすすめ拡張機能
(随時更新。これから色々と入れながら便利なものを探していく予定です。現時点では定番の物のみ以下に簡潔に記載。)
拡張機能のインストール方法
- AUTOMATIC 1111 web UI のソフト画面から「拡張機能」タブに移動
- その画面で「拡張機能リスト」タブを選び、「読込」ボタンを押す
- 拡張機能一覧が表示されるので、欲しい拡張機能をページ内検索 (Ctrl+F) で探す
- 「インストール」を押して入れたい拡張機能を導入
- 「UIの再読み込み」をする
※ 拡張機能によってはソフト自体の再起動が必要なものもあるため一度全部閉じるのが無難
※以下、各拡張機能についてリンクから当該公式 GitHub ページに飛べるようになっていますが、インストール自体はソフト側の拡張機能一覧から可能です。
(GitHub からインストールするわけではありません)
便利系
Booru tag autocompletion
プロンプト入力欄で入力候補が表示されるようになります。(入力がスムーズに。)
候補ポップアップが出たら矢印キー「↑↓」で候補選択、Tabキーで入力補完です。(単語の後ろのカンマや半角スペースまで自動で入れてくれます)
候補となる単語は Danbooru などの booru系画像掲示板のタグから表示しているみたいなので、キャラクターイラスト系の単語の入力補完向けです。
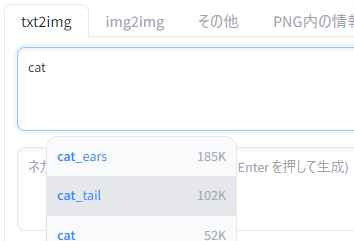
Dynamic Prompts
プロンプトでワイルドカードが使えるようになります。
単語を改行区切りで並べたテキストファイルから単語を読み取り、プロンプト中に当てはめて画像生成することもできます。
(NMKD Stable Diffusion GUI でワイルドカード機能を使っていた方は必須級の拡張機能です。ただし構文が異なるようです)
画像生成操作系
sd-webui-controlnet
線画 → 画像 や ポーズ(棒人間) → 画像 といったように生成する画像の構図(人物のポーズ)を精度良く制御できる ControlNet が使える拡張機能です。
上記青字リンク先の公式ページの下の方に色々と具体的なイメージ画像が掲載されているので、それを見ればどんな技術か分かります。
テキトーな線画にプロンプトを加えたら、AIが綺麗に清書してくれるなんて夢の工程が実現できそうで凄い…!!!
(まだちゃんと使えていませんが、これを使えば生成する画像を今までよりも思った通りにコントロールできそうです)
学習系
Dreambooth
Dreambooth は好きな画像を学習させてオリジナルモデルを作成できる機能です。
学習性能が素晴らしい反面、相応の VRAM 容量が要求されます。(12 GB ~)
※試してみたい拡張機能たち (詳細未確認)
拡張機能多すぎて全く追いきれないので、とりあえずチェックリスト代わりに気になった拡張機能をピックアップしました。
まだ試していないので実用できるものか分からないですが、試して良さげだったら整理して上に追加する予定です。
個人的に特に注目した拡張機能は1行目の概要文先頭を★マークにしています。(まだ試せていませんが…。)
| 拡張機能名 | 概要と特徴 |
| Image browser | ● web UI に Image Browser タブが追加され、今までに生成した画像がサムネイル一覧形式で表示される (生成画像履歴 兼 画像ビューア)
・ブラウザ内でプロンプト確認や画像の削除・お気に入り・ランク付けなど整理作業ができるので便利そう ・txt2img や img2img、ControlNet に画像を送信することももちろん可能 |
| Latent Mirroring | ● 生成画像が対称性を持った構図になるよう指示できるようになる
・完全に左右対称の画像を作ることも、対称度合いをスライダーで指定して生成させることも可能 |
| Smart Process | ● 縦横比が1:1でない画像を読み込み、自動で被写体を認識してトリミングして1:1にしてくれる
・写真内で最も目立つ被写体を自動で判断。被写体は人間に限定されない。 |
| DreamArtist | ★ たった1枚の画像から内容とスタイルをLoRA学習できる
・1枚の割に生成画像の品質と多様性が非常に良好 ・学習対象の画像は実写系もイラスト系も可 |
| WD 1.4 Tagger | ● 画像を読み込むと、その画像に当てはまる booru タグを提示 |
| multi-subject-render | ● 1枚の画像に複数の被写体を綺麗に配置して画像生成するのに役立つ拡張機能
・背景の生成→前景の被写体の生成→背景と被写体の合成→img2imgで仕上げ という一連の流れを簡単に実行可能 |
| depthmap2mask | ● 画像から深度を推定し、それを基に img2img 用マスクを生成
・img2img 時に手動でマスク指定して生じていた手間を大幅に削減可能 |
| Depth Maps | ● 画像から高精度な深度マップを作成
・3D Inpainting ができる |
| DAAM | ● プロンプト中の単語が生成画像のどの領域に効果を発揮しているのか、ヒートマップで視覚的に確認できる |
| embedding-inspector | ● プロンプトに使う単語を入力すると、(モデル上で)類似する効果を持つ単語を列挙してくれる
・プロンプトの類義語探索だけでなく、単語同士を混合させて新しい embedding (埋め込み表現)を作成することもできる (こっちがメイン機能かも) |
| Infinity Grid Generator | ● X/Yプロット(評価軸は2軸) よりも評価軸を増やしたグリッドを作成できる |
| Config-Presets | ● txt2img や img2img での設定値をプリセットに保存して、ドロップダウンボックスから次回以降簡単に呼び出せるようにする
・登録する設定値は指定が可能。(一部の設定値だけ呼び出すようにプリセットを作ることも可能) ・プリセット名はもちろん自由に指定可能 |
| openOutpaint extension | ● Outpainting が大変便利に実行できる専用キャンバスを web UI に追加できる
・既存の画像を好きな方向に好きな大きさで拡張できる。直感的なキャンバス操作で。 ・レイヤーシステムや領域の拡大縮小・回転といった編集機能も搭載 |
| model-keyword | ● 各モデルやLoRAで使用が必須とされているキーワードを自動で補完してくれる
・モデルやLoRAによっては特定のワードをプロンプト中に含めることで初めてきちんと効果を発揮するものもある ・そのキーワードを画像生成時に自動で後付けしてくれる (忘れる心配無し&キーワードを調べる手間の省略に) |
| Prompt Generator | ★ 入力した短いプロンプトを、詳細な画像生成に向いた長いプロンプトに変換してくれる
・例) a cat sitting → a cat sitting on a tree branch, realistic painting by … (大量にワードが続く) |
| Model Converter | ● .ckpt 形式のモデルファイルを .safetensor 形式に変換できる (変換用のタブが追加)
・fp32/fp16 の倍精度/単精度の指定や ema-only のモデル化(データの剪定) も可能 |
| Kohya-ss Additional Networks | ● LoRA を扱うにあたって有用な機能を追加
・LoRAの複数同時適用 / LoRA の領域別適用 (実験的機能) … |
| Ultimate SD Upscale | ● 生成画像のアップスケール (元からソフトにあるものとは別実装)
・ノイズ除去と不自然な人工物発生の抑止を両立 |
| Batch Face Swap | ● 画像中の顔を自動で認識して別の顔に置き変えられる |
| Promptgen | ● 入力した短いプロンプトを、詳細な画像生成に向いた長いプロンプトに変換してくれる (Prompt Generator と類似)
・プロンプト変換用モデルを複数の中から選択でき、より目的に合ったプロンプトが生成可能 (イラスト向けなど) |
| System Info | ● web UI にシステムタブを追加し、web UI のシステム情報が閲覧できるようにする
・メモリ状態、実行環境のtorch/CUDA/GPUの詳細、xformersといった重要なライブラリのバージョンといった情報を一覧で表示 ・モデルについて、モデルハッシュや Hypernetwork、Embedding 情報を表示 ・ベンチマーク実行機能もある |
| Steps Animation | ● 1枚の画像が生成する過程(ノイズから目的の画像に収束する様子)を動画化して保存できる |
| Pixelization | ● 画像をドット絵化できる (ピクセル化専用のモデルが利用される) |
| Aspect Ratio selector | ★ 画像生成画面に縦横比指定ボタンが追加され、画像サイズを手早く設定できるようになる |
| gif2gif | ● アニメGIFをimg2imgできる |
| Prompt Translator | ● プロンプト欄に日本語で入力すると、自動で英語にDeepL翻訳してから実行してくれる (※設定には要APIキー) |
| text2prompt | ★ 入力した短いプロンプトを、danbooru タグから構成される詳細なプロンプトに変換できる |
| OpenPose Editor | ★ 画像からポーズを検出し、ポーズを編集&ControlNetに送信できる |
| Latent Couple | ● 生成する画像の各領域に何を載せたいかサブプロンプトで指定することで、一つの画像に複数の要素を入れて生成できる
・領域はマウスで塗る形で好きに指定可能 ・各領域ごとに別々のプロンプトを指定することで、要素が混ざり合うことなく領域ごとに望みの要素を出せる |
| SuperMerger | ● モデルをマージした際、保存せずに直接読み込んで画像生成を実行できる
・ディスク容量を気にせずモデルのマージを試せるようになる |
| Composable LoRA | ● AND 構文と併用することで、複数LoRA使用時に各LoRAの影響範囲を特定のプロンプトに限定できる |
| Bilingual Localization | ● web UI の各項目を英語・日本語の両方併記で表示できる
・日本語化はしつつ、設定項目を探す時のために英語名でも表示して欲しい…という場合に便利 |
| LLuL | ● 画像の一部領域だけを指定して、Latent でアップスケールできる |
| posex | ● ControlNet で使うポーズ(棒人間) を作成できる |
| MultiDiffusion with Tiled VAE | ★ 少ないVRAM消費量で、元の画像に極めて忠実に高精細アップスケールできる
・各領域ごとに別々のプロンプトを指定することで、要素が混ざり合うことなく領域ごとに望みの要素を出せる (大きなキャンパスサイズでも有効) ※ 領域別プロンプトは Latent Couple にもある。違いとしては、あちらはマウスで塗る形で自由領域指定、こちらは矩形選択のよう。 |
| 3D Model&Pose Loader | ● ControlNet で使える 3Dモデル(立体人間) を読み込み・作成できる
・obj / stl / dae / fbx / vrm / glb . gltf 形式の 3D モデルデータを読み込み可 ・3D モデルを動かしてその場で編集することもできる |
| stable-diffusion-webui-rembg | ● 写真・イラストから背景を除去した画像を生成できる
・背景を除去した部分は透過状態になるので、背景の差し替えなどに使える ・背景を除去した残りの部分をマスク化する機能もある |
| 3D Openpose Editor | ● ControlNet で使える 3Dポーズ(立体棒人間) を簡単に作成できる
・ポーズだけでなく、崩れがちな手も位置を微調整して指定できる ・高さ、幅、長さなどの身体パラメータを調整して、カスタム3Dモデルを作成できる |
| text2video | ● プロンプトから動画を生成できる
※ 現状、安定して品質の高い動画を作成することは難しい |
| stable-diffusion-webui-state | ● web UI のリロード後に、入力したプロンプトやスライダーの値がリセットされないようにする |
| Aspect Ratio Helper | ● 画像のサイズ指定に便利な機能やボタンが追加される
・生成画面に縦横比指定ボタンとサイズ指定倍率変更ボタン(+50%など)が追加され、画像サイズ設定を素早く変更できる ・ 縦横比を固定した状態でサイズ変更スライダーを動かせるロックモードもある |
| Regional Prompter | ★ 生成する画像の各領域に何を載せたいか、領域ごとにプロンプトで指定することで、一つの画像に複数の要素を入れて生成できる
・画像を垂直・平行方向に分割した各領域ごとに異なるプロンプトを指定できる ・(実験的機能) 領域はマウスで描いて指定することもできる |
| Canvas Zoom | ● inpainting や sketch の画面で画像をズームできるようになる (細かい場所のマスク指定に便利)
・Shift キー + マウスホイールでズーム。ホットキーは変更可能。(これ以外の便利なショートカットも追加) |
| Abysz LAB | ● video2video 生成時、従来よりも各コマ間でのチラツキを抑える |
| PBRemTools | ★ 画像から背景を高精度に除去することができる (精度が非常に良好らしい)
・切り抜きたいものをテキストで指定して自動認識してもらう機能もある |
| a1111-sd-webui-lycoris | ● lycoris モデルを AUTOMATIC1111版ソフトで使うための拡張機能 |
| Infinite Zoom | ● 高品質な無限ズーム動画を生成できる |
| sd-canvas-editor | ● 多機能なキャンバスエディターをソフト画面に追加
・レイヤー機能、文章や画像の挿入、エフェクトや切り抜きといった編集機能を搭載 ・編集した画像は img2img や ControlNet に送れる |
| Infinite image browsing | ★ ソフトに高機能な画像ビューアを追加できる (削除や移動といったファイル操作も可)
・Prompt、Model、Lora などで画像を検索できる ・画像のパラメータを自動的にタグに変換して画像にタグ付け&検索時はタグの入力補完 ・画像生成パラメータの確認や img2img への画像の送信ももちろん可 |
| Pixel | ● 画像をドット絵化できる (使用色数の制限が可能) |
| SD-CN-Animation | ● テキストから動画(txt2vid)、動画から動画 (vid2vid) を生成できる
・動画から動画への変換の際には、ControlNet を併用して一貫性をできるだけ担保した動画を生成できる |
| !After Detailer | ● 検出モデルにより、画像から特定の要素を検出してその部分を inpaint や ControlNet inpaint に送れる
・検出モデルを切り替えることで検出対象 (2次元 or 3次元の顔、全身、手) を変更できる |
| sd-model-preview-xd | ● モデルやLoRA選択時、予め保存しておいたモデルのCivitaiページやHugging FaceページをwebUI画面で参照できる |
| One Button Prompt | ● 高品質なプロンプトを1ボタンで完全自動生成する
・ (とりあえず Stable Diffusion の実力をサクッと体感したい人向け) ・txt2img, img2img, ControlNet, Inpainting, Latent Couple に対応 |
| Model Preset Manager | ● 各モデルの推奨プロンプト/設定/トリガーワードをモデル別に保存しておける (プリセット)
・モデルの推奨設定を Civitai の該当URLを入力するだけで(ある程度の精度で)取得してくれる ・プリセットは自前で用意・編集することもできる |
| Stable Diffusion Webui Civitai Helper | ★ Civitai からモデル情報とプレビュー画像を自動で取得できる (こちらの動画を参照)
・(既に)ダウンロードしたモデルを一括でスキャンし、Civitai から情報を取得 ・モデル閲覧画面で大量のモデルもプレビュー付きでらくらく管理 ・モデル閲覧画面にはモデルのメタデータ閲覧ボタンやCivitaiページへの移動ボタンもある |
| Quick Tab Switch | ● Altキー二度押しでタブ検索ボックスが現れ、別のタブにすぐ切り替えられる
※大量の拡張機能を入れて web UI 画面がタブだらけになった方におすすめ |
| Txt/Img to 3D Model | ● プロンプトまたは画像から3Dモデルを生成する OpenAI Shap-E が web UI で使えるようになる |
※以下工事中。(実際に拡張機能を色々と試しつつ、随時追加予定)