画像生成AIの「Stable Diffusion」をパソコンから簡単に使えるソフト「NMKD Stable Diffusion GUI」 のバージョン1.11台の新機能・変更点です。
1.11.0 / (1.10.0)
2023/7/30 時点で正式リリースされている最新版はバージョン 1.11.0 です。
(※バージョン1.10.0台は開発者さんのDiscordサーバーでβ版的なノリで配布されていました。今回が半年ぶりの正式リリースです。)
↑追記:2023/7/27 にバージョン1.12.0がβ版として上記サーバーで配布されていました。SDXLモデル対応などが新機能のようです。
(更新が大変遅れてしまいすみません。)
バージョン 1.11 台では LoRA の作成と利用ができるようになりました。(画像を個人で手軽に学習でき、有志の学習データも利用できるように。)
Outpainting、定番の Karras サンプラーの追加など色々と機能が盛り込まれています。
Ver. 1.9.1 → Ver 1.11.0 の変更点
※以下要点です。正式リリースされなかった 1.10.0 での更新内容も含みます。(公式情報はこちら参照)
※ソフトダウンロード先:NMKD Stable Diffusion GUI - AI Image Generator
新機能の追加
- Stable Diffusion 2.0/2.1 モデルの利用に対応
- Outpainting 機能追加
↑画像を任意の方向に自然に拡げる (画像の外側を自然に描き足す機能) - Karrasサンプラーの追加 (DPM++ 2M Karrasなど)
- LoRA と LyCORIS の読み込みに対応
- LoRAトレーニングがソフトでできるように
↑元々あったDreamboothによるモデル訓練機能は削除 - 生成する画像が対称になるように指定できるオプション
- モデルのClipレイヤーの最後のレイヤーをスキップできるように (Clip Skip値:2 に対応)
- 画像を読み込む際に特定色を透明として読み込めるように
- クリップボードから透過画像を読み込めるように
- .ckpt形式以外のモデル (Diffusers形式や .safetensors形式) も直接読み込めるように
- Diffusers形式でも好きなVAEが読み込めるように
- プロンプトを77トークンより長くできるように (実験的機能)
- Seed値の最大値が 4294967295 から 9223372036854775807 に
- Textual Inversion の新形式の読み込みに対応
利便性改善
- 画像の最大解像度とプロンプト履歴の上限が増加
- Huggingface Diffusers モデルを直接ダウンロードできるツール
↑いちいち git clone してくる必要がなくなった - 生成された画像を自動削除するオプションが追加(お気に入りフォルダにコピーされていない場合)
- InstructPix2PixとSD ONNXで、実行ごとにモデルをいちいち再読み込みせず済むように
- ソフトがアップデートに対応し、更新作業が楽に(※今までは更新の度に再インストールが必要だった)
- 設定ファイル「settings.ini」が追加され、解像度の上限など特定の設定の制限値を調整できるように
- UIが折りたたみ可能なカテゴリーに分割され見やすく
不具合修正
- ソフト画面チラツキの改善
- 大量のバグ修正
公式情報(英語)
ソフト使い方ガイド(公式):NMKD Stable Diffusion GUI
LoRA 訓練ガイド(公式):LoRA Training GUI
ソフト更新履歴(公式):changelog
※基本事項
初めて NMKD Stable Diffusion GUI を使う方はソフト最新版のインストール方法・基本的な使い方など一通りまとめた以下のページを先にご確認ください。
入力したテキストから画像を生成したり、自分が描いた落書きに説明テキストを加えれば思い通りの絵に変えたりできるAI「Stable Diffusion」 ↑a sleeping cat in the hot spring (温泉で眠る[…]
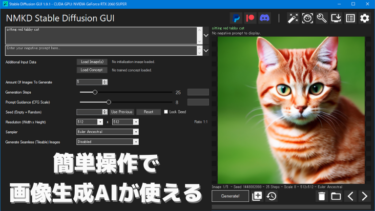
画面の各項目や設定画面 (Settings) のマニュアルは以下のページです。(画面がちょっと古いですが)
画像生成 AI「Stable Diffusion」をコマンド不要で簡単操作で使えるソフト NMKD Stable Diffusion GUI について、ソフト画面と機能・仕様を一覧で説明しています。 こちらのページは機能や設定を一通り[…]
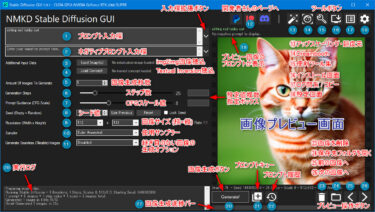
※ 他バージョンで追加された新機能
他のバージョンの追加機能を確認したい場合は以下のページをご覧ください。(画像クリックで該当ページに移動できます)








NMKD Stable Diffusion GUI 記事一覧
以下、本ページではバージョン1.11.0 の新機能に絞って概要や使い方を説明していきます。
※今回いつもの更新より変更点が多すぎるため、各変更点の説明をいつもほど詳しくできていません… ごめんなさい。
※いくつかの機能が自分の環境ではエラーなどで使用できていません…。
Outpainting
画像の外側を自然に描き足してもらい、画像を拡げる機能です。
Outpainting の方法
まず、Outpainting したい画像をソフトにドラッグ&ドロップするか、Load Image(s) ボタンから読み込ませます。
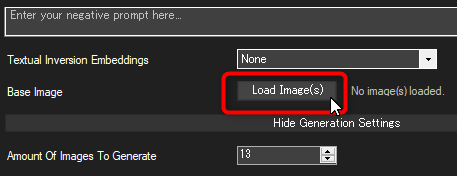
※生成したばかりの画像を読み込ませたいなら、画像プレビュー画面で右クリック→ Use as Initialization Image で今プレビューしている画像を読み込めます。
読み込みオプションが Load Image (画像を読み込む) になっていることを確認して、画面の「OK」をクリックします。
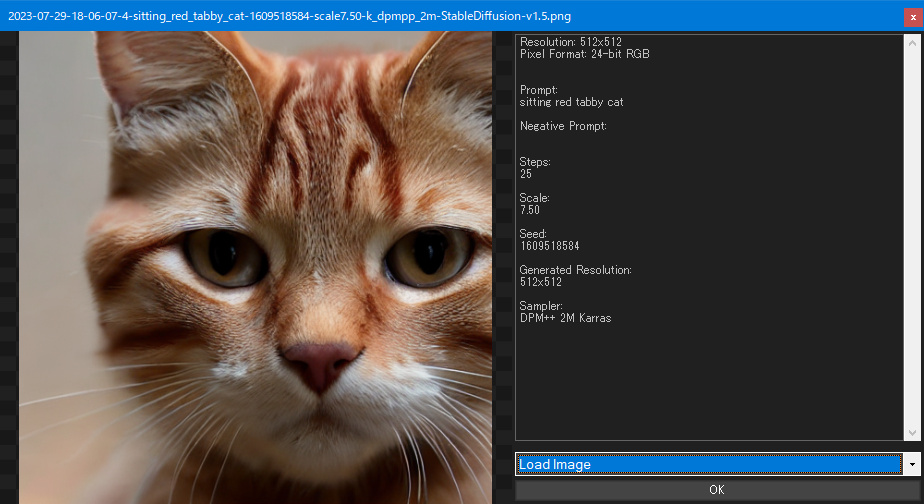
画像を読み込むと、ソフト画面の設定項目欄の並びが変わります。
「Image Usage」(画像の利用方法) のオプションを、Outpainting に変更します。
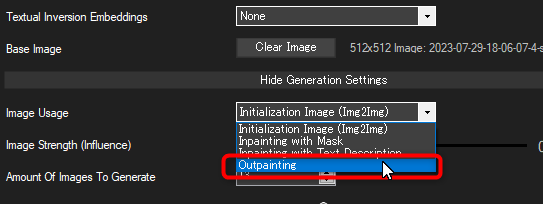
これで Outpainting 用のモードになりました。
隣に「Extend Image From...」(画像の拡張方向) のオプションが表示されるので、拡張前の画像がどの位置に相当するのかを指定してください。
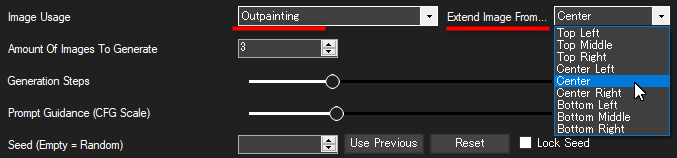
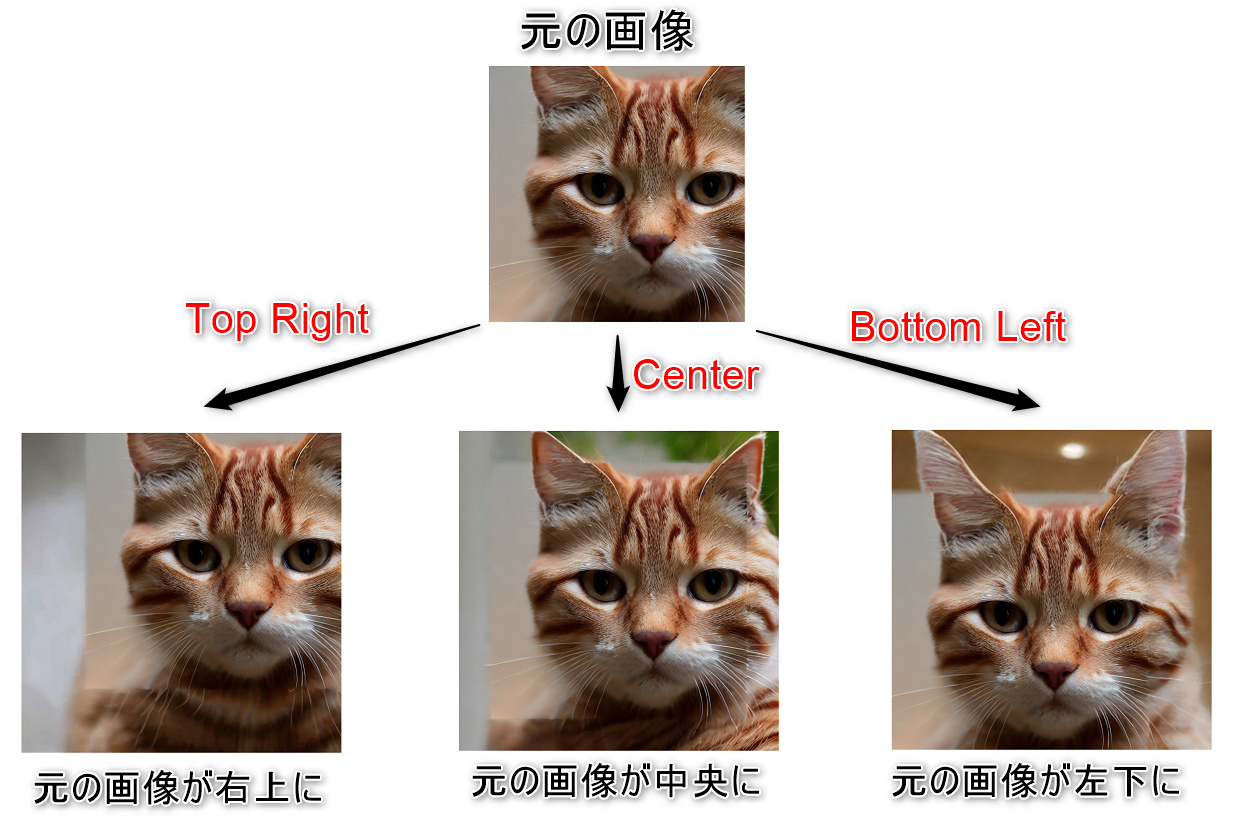
どれがどの方向になるのかは以下の画像のとおりです。
最後に、忘れずに拡張後の画像サイズを指定してください。(もちろん読み込んだ元の画像のサイズよりも大きくする必要があります)

ちなみに例えば 512×512 を4倍のサイズ (1024×1024)にすると、画像生成の所要時間がかなり伸びます。
肝心の生成結果ですが、元の画像の境界線がどうしてもはっきり出てしまうため自然な感じに仕上げるのは難しそうです。
ねこさんのお耳もサイズが元の画像と合っておらず不自然です。

使ってみた感じ、顔のアップ画像の拡張は Outpainting に不向きみたいです。
自然の風景や星空など遠景を拡張する方が良さそうです。

↑でも境界線は結構はっきり見えちゃってます。
Stable Diffusion 2.1 モデルの利用 (※自分の環境では使えず)
ソフトに同梱されている Stable Diffusion 1.5 モデルより新しい、バージョン2台のモデルもソフトで利用可能みたいです。
※プロンプトのコツを含め使い勝手が 1.5 の時とは全然違うようなので、単純な上位互換という訳ではなさそうです。利用はお好みで。
※私の環境ではエラーが出て使えませんでした…。以下の方法で他のユーザーさんができるかどうかも不明です。
Stable Diffusion 2.1 のダウンロード
Stable Diffusion 2.1 の公式ダウンロード先は以下リンクから。
リンク:v2-1_768-ema-pruned.safetensors
ダウンロードした .safetensors ファイルを、モデルフォルダの中に移します。
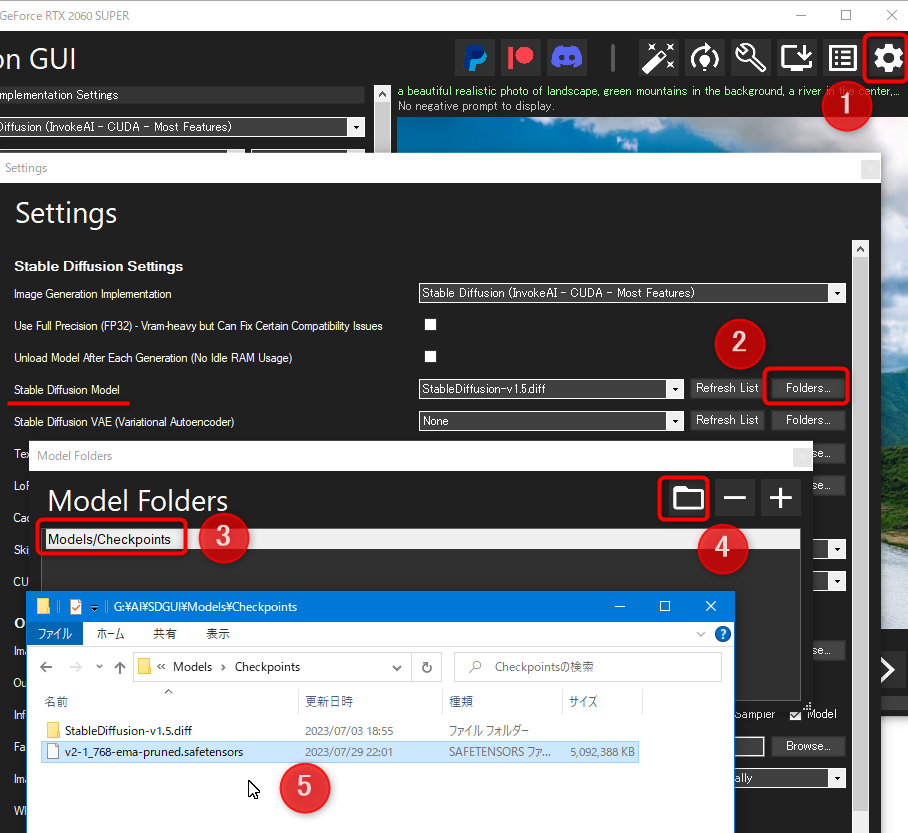
- 設定ボタンをクリック
- Stable Diffusion Model 項目の「Folders...」ボタンを押す
- モデルフォルダ一覧画面が出るので、リスト中のモデルフォルダをクリック
- フォルダボタンをクリック
- モデルフォルダの場所が開かれるので、ここにダウンロードしたモデルファイルを入れる
モデルの使用方法
Model Name/Version の設定項目で、今ダウンロードしたモデル(v2-1_768-ema-pruned.safetensors)を選択すれば Stable Diffusion 2.1 モデルが使えます。
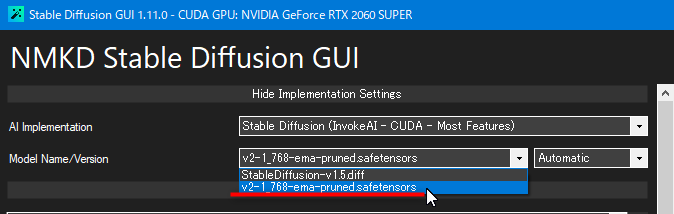
※上記設定項目が見当たらない(隠れている)場合は、一番上の「Implementation Settings...」をクリックすれば隠れていた設定が表示されます。
※自分の環境で発生したエラー
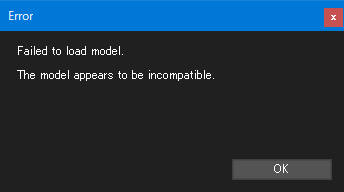
モデルの読み込みに失敗。(モデルに互換性が無いと表示)
何度か適当にいじっていたら画像生成は行われましたが、真っ黒な画像しか生成されませんでした…。
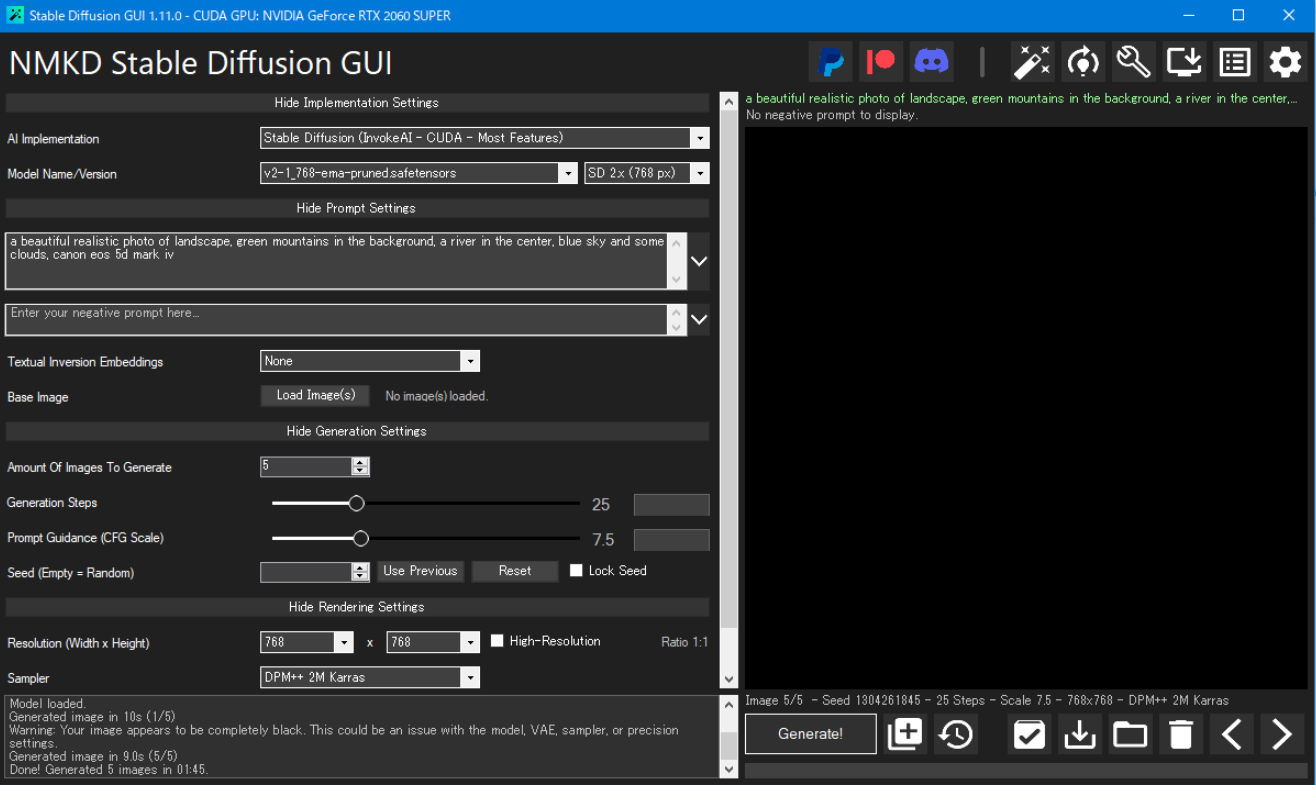
この症状が自分だけなのか他のユーザーでも発生するのかは分からないですが、とりあえず代わりの方法が見つかるまでは Stable Diffusion 2.1 のモデルファイルは使えそうにないです…。
使用できるサンプラーの追加
画像生成時に使用できるサンプラーに、しばらく前に利用者が増加した Karras 系サンプラー等が利用できるようになりました。
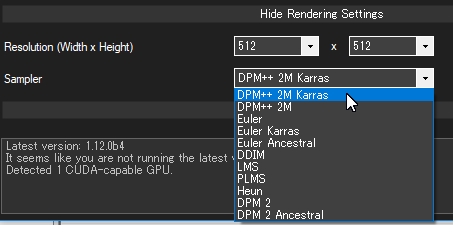
DPM++ 2M / DPM++ 2M Karras / Euler Karras が使えるようになりました。
EasyNegative 利用でネガティブプロンプト省略
ネガティブプロンプトに色々と指定して画像の質を上げるテクニックがありますが、それをやる代わりに EasyNegative と呼ばれるファイルを利用すれば同様の効果をネガティブプロンプト無しで発揮できます。
※どんな画像でも質がアップするわけではありません。例えば風景写真やねこ写真に EasyNegative を適用しても質が上がらないどころかかえって変な画像が生成されやすくなります。(人物が混入するなど)
ネガティブプロンプト省略用のファイル (Textual Inversion Embeddings) は EasyNegative に限らず色々な種類がありますが、得意とする生成対象がそれぞれ異なるので注意。
(キャラクターイラスト(人間)が主な対象っぽいです)
EasyNegative 使用方法
設定項目「Textual Inversion Embeddings」のところを None (使用しない) から EasyNegative に変更してください。
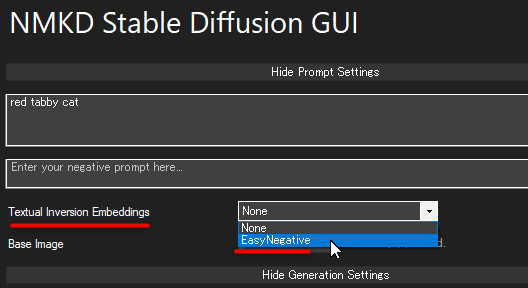
隣に「Append To Prompt」ボタンが現れるので、それを押すとプロンプトに「<EasyNegative>」が追加されます。
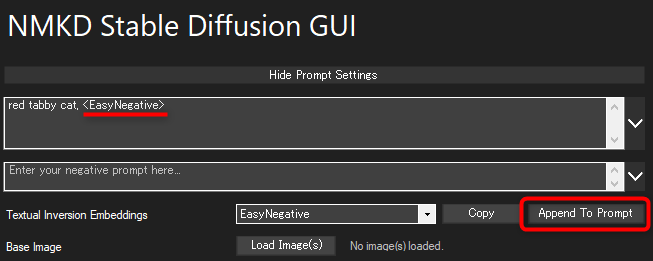
あとはこの状態で画像を生成すればOKです。
EasyNegative はネガティブEmbeddingsなので、プロンプト欄ではなくネガティブプロンプト欄の方に「<EasyNegative>」を追加する必要がありました。
ネガティブプロンプト欄の方に <EasyNegative> を移してから画像生成してください。
(誤情報を載せてしまいすみません)
他の Textual Inversion Embeddings の利用
ソフトに同梱されている EasyNegative 以外の物も利用可能です。
Webでダウンロードした Textual Inversion Embeddings ファイル (拡張子 .pt) を、Modelsフォルダの中の Embeddings フォルダの中に入れればOKです。
LoRA / LyCORIS の読み込み
既存のモデルに画風やオリジナルキャラクターなどを追加学習させた LoRA ファイルや LyCORIS ファイルを読み込み、画像生成に利用することができます。
NMKD Stable Diffusion GUI での LoRA / LyCORIS 利用方法
まず、LoRAファイルを用意します。(.safetensors形式のみ対応)
それを Models フォルダの中の LoRAs フォルダの中に配置します。
(今回は例えば loraSample01.safetensors という名前の LoRA ファイルを入れたとします)
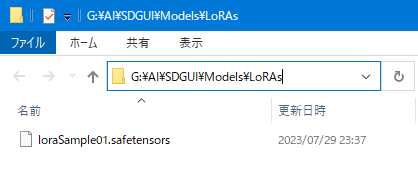
続いて、ソフト画面で F5キーを押して画面を更新します。
すると、LoRA 選択オプションが画面に現れます。(※現れない場合は一度ソフトを再起動してください)
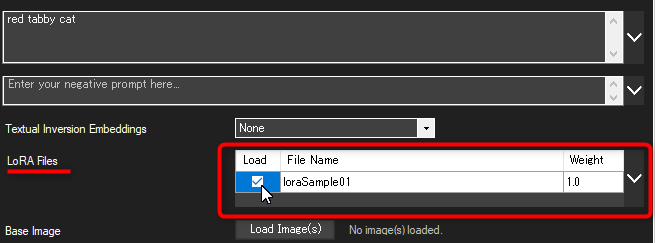
LoRA フォルダに入れた LoRA ファイルがリスト形式で一覧表示されるので、画像生成に使いたい LoRA だけチェックボックスにチェックを入れれば準備完了です。
この状態で画像生成すれば、LoRA が適用された状態で画像が生成されます。
フォルダに新しいLoRAファイルを入れた場合は、また F5 キーを押せばリストが更新されます。
※LoRAが表示しきれていない場合はマウスホイールでスクロールするか、右にある「 V 」ボタンを押して表示領域を広げてください。
LoRA 学習
ソフト単体で LoRA ファイルの作成もできるようになったみたいです。
例えばおうちのねこちゃんの写真を学習させて LoRA ファイルを作って、ねこちゃんが有名な観光地や月面、宇宙にいる写真とか生成したら楽しそう!!/ᐠ˶>ω<˶ᐟ\
自分が描いたオリジナルキャラを LoRA 学習させて Stable Diffusion でアレンジしてみるのも楽しいかも。
※私の方ではまだ試せていないので、以下、概要のみ記載しています。公式マニュアルはこちら↓
Somewhat modular text2image GUI, initially just for Stable D…
推奨システム要件
- GPU: 8 GB VRAM を搭載した Nvidia GPU、Turing アーキテクチャ (2018) 以降
※ VRAM 6 GB でも動作報告あるみたいなのでギリギリ動くのかも - RAM: 32 GB の RAM (16 GB も一応可)
↑VRAM 24 GB 以上が推奨されていた Dreambooth に比べたら LoRA での学習はだいぶ要求スペックが低く済みます。
トレーニング方法
訓練用画像の準備
訓練用の画像は5~100枚が推奨で、量より質と念押しされていました。
画像サイズや縦横比はあまり重要ではないようですが、学習させたい被写体以外の不要な物が映り込まないようにすることが重要みたいです。
訓練させたいキャラクターや物をさまざまなポーズやシナリオで表現した画像を使用してください。
背景にもバリエーションがあったほうが良いようで、全画像の背景が真っ白だとモデルが別の背景を生成するのが難しくなるみたいです。
<良くない画像の例>
- 低画質の画像
- 訓練対象の被写体がはっきりしない乱雑な画像
- 変わったポーズ
LoRA 訓練画面を開く
LoRA の学習画面には、ソフト右上の赤枠で囲ったボタンをクリックすれば移動できます。
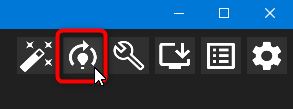
LoRA トレーニングの画面が開きました。
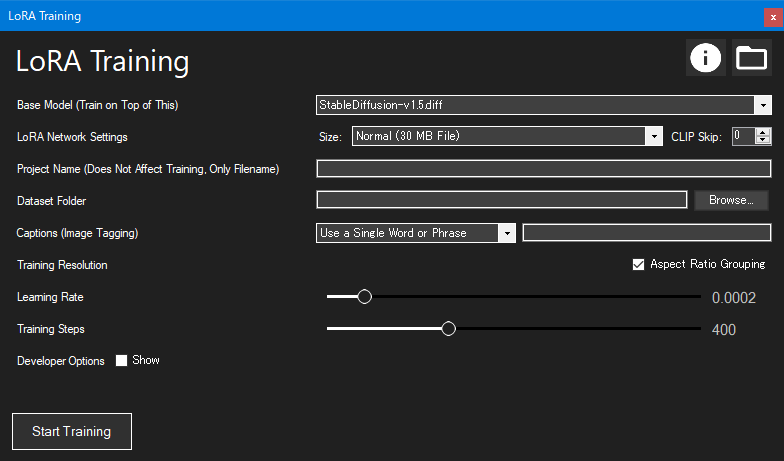
各設定を調整する
Base Model (Train on Top of This)
ベースとするモデルの選択です。
テンプレートとして使用するモデルを設定します。訓練対象の新しいキャラクターや物が選択したモデルの中に追加されます。
モデルには、実写系なら Stable Diffusion 1.5、2D アートには animefull-final が推奨されています。
LoRA Network Settings
LoRAの品質設定の選択です。
訓練には本来様々な設定値を手動で調整する必要があるのですが、操作を簡単にするために開発者さんが調整済みの設定(プリセット)をいくつか用意してくれています。
ファイルサイズが大きいLoRA設定ほど生成するLoRAの質が高くなる一方、訓練自体に時間がかかります。
最も良い品質のプリセットが推奨されています。
| 選択肢 | 品質 | 所要時間 |
| Tiny (7.5 MB File) | 低 | 最短 |
| Small (15 MB File) | 中 | 短 |
| Normal (30 MB File) | 高 | 中 |
| Big (60 MB File) | 最高 | 長 |
また、CLIP Skip という設定値がありますが、これはベースとするモデルと値を一致させる必要があります。
Stable Diffusion 1.5 ベースのモデルの場合は 0、NovelAI ベースのモデルの場合は 2 とのこと。
Project Name
LoRA ファイルのファイル名の設定欄です。(ファイル名にのみ使用され、訓練には影響しません)
Dataset Folder
訓練用画像の入ったフォルダを指定します。
Captions (Image Tagging)
キャプション (学習させる画像が何の画像なのか説明するテキスト) の指定方法についての設定です。
例えば自分の家のサバトラにゃんこの写真を学習させたいとき、キャプションに「silver tabby cat」(サバトラ猫)と指定することで学習精度の向上や学習結果のコントロールが可能になります。
設定は以下の3つから選択できます。
① No Caption
キャプションを使用しません。(仕様上は、空のキャプションを設定しているみたいです)
この場合、LoRAを実際に利用する際にたとえプロンプトに cat といった単語を一言も入れていなくても、LoRA 学習したねこさんの画像に強く影響を受けた画像が出力されます。
つまり、LoRA が常に画像に影響を与えることを意味します。(影響のコントロールができない)
② Single Phrase
全ての画像に対して共通の一つのキャプションを設定します。
この選択肢を選ぶと隣に入力ボックスが出現するので、そこにキャプションを入れればOKです。
(「silver tabby cat」など、学習させた画像が何の画像なのか表すキャプションを入力する)
学習後、LoRA利用時は例えば「jumping silver tabby cat 」(跳んでいるサバトラ猫) といった感じでキャプションにプラスαする形でプロンプトを指定すれば生成する画像をある程度コントロールできます。
③ Read Captions from TXT Files in Training Folder
画像1枚ごとにそれぞれ異なるキャプションを設定します。(面倒な代わりに一番コントロールが効く)
訓練画像と同じ場所にある同名のテキストファイルから、キャプションを読み取って使います。
例えば画像ファイル名が image01.png なら、image01.txt という同名のテキストファイルを画像と同じ場所に配置して、そのテキストファイルの中身にキャプションを書き込めばそれがキャプションとして学習時に利用されます。
画像ごとに「座っているサバトラ猫」「目を閉じて眠っているサバトラ猫」などのキャプションを設定することで、より正確に学習できます。
Training Resolution
Aspect Ratio Grouping のチェックボックスをONにすると類似した縦横比の画像がグループ化されるため、トレーニングがより効率的になるらしいです(詳細不明)
Learning Rate
画像がどの程度「積極的に」トレーニングされるかを制御する設定値です。
Learning Rate が高すぎるとオーバーフィットしてしまい訓練画像とほぼ同じ画像しか出力できない柔軟性に欠けるモデルになってしまったり、視覚的な品質が低下してしまったりする場合があるようです。
また、訓練画像が複雑であるほど Learning Rate の値を大きめにしないといけないようです。
Training Steps
訓練を何ステップで行うかという設定です。
ステップ数が多いほど生成するモデルの質が高くなる一方、訓練自体に時間がかかります。
訓練の開始
設定が終わったら、画面左下の「Start Training」ボタンを押して訓練を開始してください。
訓練が終わるとLoRAファイル (.safetensors) が生成するのでこれからの画像生成で利用できます。
生成画像の対称化設定
生成する画像が対称になるように指定できるオプションが追加されました。
一番下の「Symmetry Settings」(対称性の設定)の欄にある「Generate Symmetric Images (Mirror Axis)」(対称的な画像を生成する) の設定を変えれば、生成画像を対称化できます。
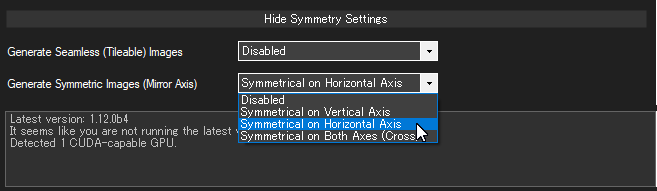
| Disabled | 無効 |
| Symmetrical on Vertical Axis | 左右対称にする |
| Symmetrical on Horizontal Axis | 上下対称にする |
| Symmetrical on Both Axis | 上下左右対称にする |
例えばこちらは風景写真の生成時に「Symmetrical on Vertical Axis」(左右対称) を指定した例です。
画像が左右対称に生成されました。

↑でもよく見ると写真右半分は若干歪んでいます…。不具合かな…。
モデルの Clip Skip 値の指定
注意:この機能に対応しているのは Diffusers 形式のモデルのみです。(.ckpt や .safetensors 形式は非対応)
※必要な方のみ以下の説明をお読みください。
モデルの Clip Skip 値を指定できるようになりました。
Settings (設定) 画面の「Skip Final CLIP Layers」オプションを変更すればOKです。

| 設定 | 意味 | 相当する Clip Skip 値 |
| Disabled | CLIPレイヤーをスキップしない | 1 |
| Skip Last Layer | 最後のCLIPレイヤーをスキップ | 2 |
| Skip Last 2 Layers | 最後から2つまでのCLIPレイヤーをスキップ | 3 |
| Skip Last 3 Layers | 最後から3つまでのCLIPレイヤーをスキップ | 4 |
Huggingface Diffusers モデルのDLツール (※動作せず…)
※私の環境では動作せず使えませんでした…。以下、方法のみ記載します。
こちらのリンク先のような Hugging Face というサイトから Diffusers 形式のモデルを直接ダウンロードできるツールみたいです。
NMKD Stable Diffusion GUI では Diffusers 形式のモデルが .ckpt や .safetensors 形式よりも高速で推奨されています。
しかし Diffusers 形式のモデルは単一のファイルではなくフォルダにまとめられた複数のファイル群から成るので、用意がちょっと面倒です。
本来はこのダウンロードツールで Diffusers モデルのダウンロードが簡単に済むはずなのですがなぜか自分の環境では正常に動作せず…。
方法
ソフト画面上部のこちらのボタンからメニューの「Download Huggingface Model」をクリックします。
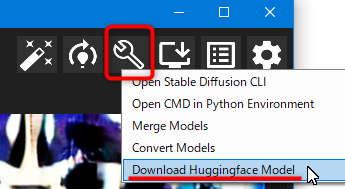
ダウンロード画面が開くので、入力ボックスにダウンロードしたいモデルの Huggingface ページURLを入力し、OKをクリックします。
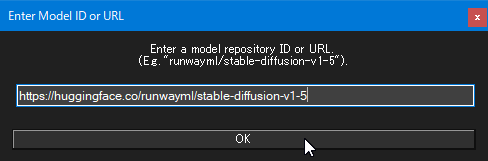
するとコンソール画面 (黒背景に白文字の画面) が立ち上がり、ダウンロードの進捗が表示されます。
本来はこれでモデルがダウンロードされるはずなのですが、私の環境ではダウンロードしたはずのモデルがどこにも存在せずDLに失敗していました。
※SDGUI\Data\cache\ フォルダに残骸らしきものはありましたが…。
ソフトのアップデート
注意:以下の手順ではソフトをβ版にアップデートしていますが、私の環境ではβ版アプデ後に画像生成ができなくなってしまったのでβ版へのアプデは非推奨です。
本バージョンから、ソフトが「更新」に対応しました。(今までは新しいソフトを毎回再インストールしていた)
ソフト右上のこちらのボタンからメニューの「Install Updates」をクリックして、アップデート画面を開きます。
アップデート画面が開きます。
リストからどのバージョンに更新したいか選んだ後、「Install Selected Version」ボタンを押せば更新が始まります。
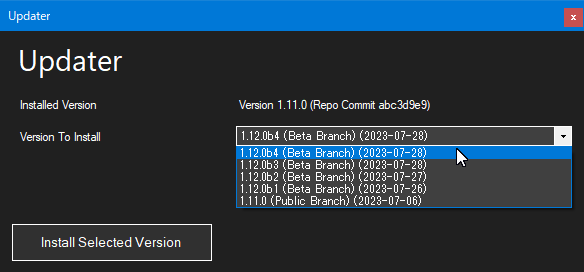
なお、(Beta Branch) と付いているものはβ版です。
更新作業中はソフトの操作ができなくなるので、少し待ちます。(一度ソフトが再起動します)
しばらく待つと更新が完了します。(自分の環境では 1.11.0 → 1.12.0b4 への更新が3~4分程度でした)
設定ファイル settings.ini
設定ファイル「settings.ini」が追加され、解像度の上限など特定の設定の制限値を調整できるようになりました。
ソフト本体と同じ場所に settings.ini はあります。

各設定値の上限を指定できます。(設定を反映させるためには多分ソフトの更新が必要です。)
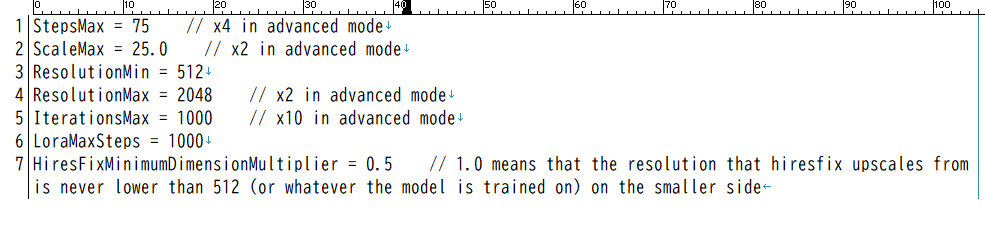
初期値は上記画像のとおりになります。
設定画面で advanced mode (上級者モード) を有効にすると、settings.ini に記載されている倍数まで設定値上限が跳ね上がります。(例:ステップ数なら 4倍)